The Relay Race
Demand at software speed, supply at physical speed: where to sit in the AI infrastructure stack


Two readings of AI infrastructure dominate the current debate. Both rest on category errors. The first is the glut thesis: the $700 billion gap between projected hyperscaler capex and any defensible revenue path, and therefore a commodity-style clearing event within the next two or three years. The arithmetic is coherent, but the category is not. The buildout would resemble prior commodity cycles such as fibre, DRAM, and shale only if the two sides of the market respond at similar speeds. They do not: demand for AI infrastructure responds at software speed; supply responds at physical speed; and that asymmetry has no close analogue in the cycles the glut thesis pattern-matches to. The cost of being wrong on the glut thesis is stepping out of a general-purpose-technology deployment in its early innings.
The second reading is bottleneck commentary: the steady weekly diet of analyst notes on the next constraint to clear, with power this month, transformers next quarter, HBM by 2028, treating each binding layer as the trade. This is closer to the truth than the glut thesis, but it has its own characteristic error. It treats each bottleneck as a milestone to be cleared rather than as one phase in a moving system, and it tends to pull investors into the most crowded position at the moment the rent is most visible. The cost of being wrong here is getting caught long the wrong layer when the binding migrates, or, more dangerously, getting caught at the one layer where the supply response can actually arrive (as may well occur at the neocloud or other ‘financing moat’ layers).
The asymmetry between demand and supply response times produces neither a clearing market nor a sequence of milestones, but a relay race: a succession of binding constraints, each ceding to the next, with the locus of pricing power moving through the stack on a timescale measured in decades rather than years, as in electricity and oil and gas. The race is, within reasonable bounds, predictable, because the response functions of the physical inputs are knowable. It also produces three categories of winner whose advantages differ in durability, a distinction that matters most for long-duration capital. Some positions earn rent only while their specific constraint binds. Others carry an advantage that outlasts the binding period, re-rating during their turn and keeping the rating against a much larger market once the buildout matures.
1. The asymmetry
Demand for AI infrastructure responds at software speed while supply responds at physical speed. When inference prices fall, the market for applications using that inference expands within weeks, because the decision to deploy more is a procurement decision made by software teams inside the deployment windows of their engineering cycles. When more capacity is needed, the decision to build it runs into gas turbine backlogs, FERC timelines, electrical steel prequalification cycles, ASML throughput, and TSMC yield curves, none of which compress to the speed capital would like, regardless of how much capital is deployed.
The aggregate data is already consistent with this. The price of a GPT-4-class model has fallen by roughly a factor of 1,000 in two years (Demirer et al., 2025), and rather than producing saturation this has been accompanied by continued exponential growth in usage. Enterprise spend on generative AI has risen more than threefold over the same period, inference spend has overtaken training, and computing capacity devoted to AI has continued to double every 7 months. Electricity behaved this way across the twentieth century: unit costs fell by roughly two orders of magnitude between 1900 and 1960, and electricity did not find a new equilibrium at the lower price but became the substrate for industrial motors, urban rail, refrigeration, appliances, electrochemistry, and eventually the computing infrastructure on which this is being read. Intelligence is behaving the same way, and the category it belongs to is general purpose technology deployment, not commodity buildout.
Both errors named in the opening, the glut frame and the bottleneck frame, show up clearly in recent pricing cycles. H100 spot rates fell from roughly $8 per hour in early 2024 toward the $2–$3 range through 2025, and the glut commentators read this as the demand crack they had been forecasting. The bottleneck thinkers who had been chasing GPUs as the trade were simultaneously caught flat-footed: by the time the H100 spot dip was visible, the binding constraint had already migrated to power, and Microsoft acknowledged publicly that it now held GPUs it could not plug into the grid. The H100 trough was a product-cycle handoff inside a generational transition. By early 2026, H100 contract pricing had rebounded roughly 40% as the Hopper-to-Blackwell transition completed and the secondary market cleared. DRAM showed the same pattern on a different clock: the 2023 spot-price trough was read as structural oversupply at the time, and pricing had fully reset within 12 to 18 months as AI memory demand absorbed the slack. In both cases, the apparent glut was the asymmetry operating exactly as it should, and the bottleneck thinkers who had been long the layer in question were the ones who paid for the misreading.
What the commodity-buildout template misses is that under this response asymmetry, supply and demand do not clear in the usual sense. Each capacity addition activates a use case that the previous cost structure could not support, and the frontier of unactivated use cases recedes roughly as fast as new capacity arrives. The buildout continues until either the physical inputs commoditise at the rate demand expands, which in electricity took 80 years, or the GPT itself matures into a different consumption pattern. In the meantime, the system is permanently running against a constraint somewhere in the stack. Capital deployed at the constrained layer earns rent for as long as the constraint binds. What the bottleneck template misses is that the constraint moves, and the rents move with it. Understanding both the mechanism and the sequence is the entire analytical problem.
2. The relay race
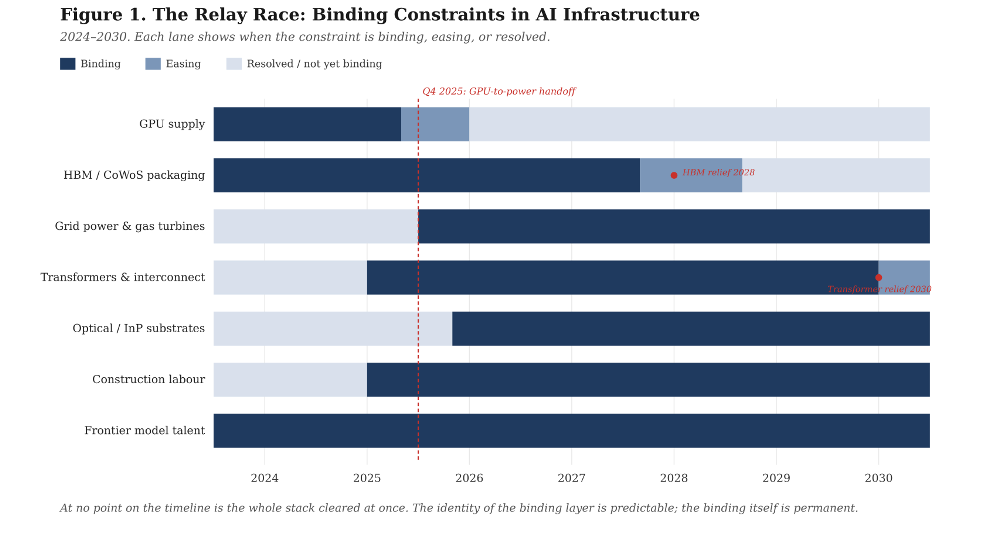
Because the constraints are physical, they do not all bind at once. One constraint binds until the capacity response catches up, at which point demand, having grown into the earlier capacity, binds the next. The locus of scarcity is a moving target, and the question for any asset is where in the sequence it sits.
The historical case most often cited as a cautionary tale against this thesis is the internet fibre buildout of 1996 to 2002. The received reading is that telecoms overbuilt, fibre became worthless, and the lesson is that infrastructure cycles end in gluts. The data tells a different story. At the peak of the overbuild, only between 2% and 5% of laid fibre was carrying traffic, and long-haul transit prices collapsed from roughly $1,200 per megabit per second in 1998 to under $1 by 2015. The equity loss was genuine. But the dark fibre did not stay dark. By 2010 it was fully utilised. Demand grew into the capacity on a timescale of about a decade, and what looked like durable oversupply in 2002 was, in retrospect, early delivery of a capacity layer whose commoditisation was the prerequisite for the next layer to emerge.
The next layer was the content delivery network. Akamai’s revenue went from $4 million in 1999 to $163 million by 2003, to $636 million at the YouTube streaming inflection in 2007, and to $1.37 billion by 2010. Fibre had commoditised; CDN had not, because its binding constraint was operational knowledge about edge placement and caching rather than capital-responsive physical capacity. The handoff then occurred again, from CDN to colocation, colocation to cloud, and cloud to the current generation of AI compute. At no point in the 25 years that followed did a system-wide glut materialise. The fibre overbuild, read correctly, is not the cautionary tale against the infrastructure thesis. It is the clearest available precedent for it.
Electrification tells the same story over a longer arc and with higher amplitude. The buildout from 1880 to 1960 proceeded through overlapping constraint phases. Generation was binding from roughly 1880 to 1910, and the Insull-era utilities that built the first central stations earned extraordinary returns. By the 1920s generation had commoditised (the apparent glut), and the binding constraint had migrated to transmission and distribution. Copper consumption for T&D alone rose from 60 million pounds in 1920 to 260 million pounds in 1930, a 400% increase even as generation growth slowed. Firms indexed to the new binding layer compounded through the Depression. General Electric’s sales doubled between 1921 and 1929; its earnings-to-sales ratio held steady at 13–14% from 1920 all the way through 1940. Sangamo Electric, whose business was meter manufacturing for the expanding utility market, grew employment from 1,200 in 1929 to 3,000 by 1943, through the Depression. By the 1940s, the binding constraint had migrated to distribution equipment and end-use. By the 1960s, to load management. 80 years of compounding returns were distributed across a succession of layers, and the investors who fared best were those who understood that the binding constraint was a moving target rather than a permanent address.
The useful property of the current cycle for an investor is that the sequence is visible in advance. As of early 2026, the near-term binding constraints, in approximate order of severity and duration, are grid power and gas turbine capacity (5–10 year lead times, structurally the longest); large power transformers and grid interconnection (3–7 years, Wood Mackenzie’s 30% supply deficit holding through the decade); HBM memory and CoWoS advanced packaging (18–24 months, easing by 2028 as Micron’s Idaho fab comes online); indium phosphide substrates for optical networking (2–3 years, worsening as co-packaged optics compound demand); data centre construction labour (a 439,000-worker shortfall against a workforce with 41% retiring by 2031); EUV lithography and advanced-node logic (3–5 year fab cycles, stable but concentrated); and frontier model training talent (fewer than 500 senior practitioners globally). Each constraint has a knowable response function. Which layer binds at any given moment determines where pricing power sits.
Microsoft’s acknowledgement that its binding constraint has shifted from GPUs, which it now holds in inventory, to power, which it cannot plug them into fast enough, is the relay race in real time, disclosed by the most data-rich operator in the stack. The bottleneck thinker who was long GPUs in mid-2025 is the trade most exposed to handoffs of this kind. The relay-race thinker is positioned to anticipate them.
3. Three kinds of winners, two kinds of rent
If the relay race is the right description of the buildout, the next question is which positions earn rent only while their specific constraint binds, and which earn rent during their binding period and then keep the re-rating against a larger post-buildout market. The relay race produces three categories of winner. Two extract rents that are temporary, tied specifically to their constraint being the binding one at the moment. The third earns the same temporary rent while its constraint binds but carries a durable advantage that outlasts the binding period. This is the payoff pattern that matters most for long-duration capital, and the one the market mis-prices. One distinction is worth making first. A competitive advantage is a structural feature that cannot be replicated within the investment horizon. A rent is what that advantage extracts given the current demand environment. TSMC had its process-knowledge advantage in 2019, but the rent was smaller than it is now because HPC demand was not yet stressing the leading-edge node. The advantage persists across cycles; the rent is the advantage multiplied by the scarcity conditions of the moment.
The first category holds scarce physical or regulatory positions that cannot be replicated within the cycle. The natural gas pipeline network connecting producing basins to the load centres emerging around hyperscale campuses is Ricardian in this sense: the rights-of-way were established decades ago, FERC certification of a new interstate line takes years, and the long-term (10–20 year) supply and power agreements pipeline operators are signing with hyperscalers, including the Williams-Meta agreement and the Energy Transfer-Oracle deal, price at reservation rates that do not respond to incremental capex elsewhere in the system. Generation sites with existing grid interconnection are Ricardian because the queue to obtain new interconnection runs at medians above 4 years against a national backlog of 2,300 gigawatts. Cleveland-Cliffs’ Butler Works is Ricardian as the sole North American source of grain-oriented electrical steel, feeding a transformer supply chain in which demand is up 116% since 2019 and the physics floor on new GOES capacity is 5 to 7 years.
Ricardian advantages are defensible against technological change because the scarcity is physical or legal rather than technical. A better algorithm does not compress a FERC timeline or create new electrical steel mills. The rent, however, is conditional on the specific output remaining in demand and on the regulatory regime that creates the barrier holding in place. A shift in fuel mix, routing, or regulation can reset the rent without eroding the underlying advantage. The position earns extraordinary returns while its layer is binding and reverts toward competitive economics when adjacent capacity eventually arrives.
The second category holds a technology-frontier lead. Coherent’s architectural lead in 800-gigabit and 1.6-terabit optical transceivers, with book-to-bill above 4× and most of 2026 booked, reflects a technology lead the field has not yet closed. Vertiv’s liquid-cooling architecture and Eaton’s electrical balance-of-plant for high-density AI racks (dollar content per megawatt up from $1.2 million in the cloud era to $3.4 million in AI) earn from being first to the required technical specification. These are Schumpeterian rents. The rent flows while the lead holds, and the lead holds only as long as the incumbent keeps running. The field catches up because the constraint driving the rent is technical rather than physical; an architectural discontinuity can reset the curve altogether. These are real earnings, but an investor pricing them as durable is pricing them wrong.
The third category, the one most consequential for a long-duration book, holds accumulated operational know-how that competitors cannot buy in factor markets, cannot recruit out of any single labour pool, and cannot compress the clock on. The canonical case is TSMC. At the 3-nanometre node it achieves yields approaching 90%. Samsung, having deployed more than $200 billion in capital, still struggles to hit 50%. On a 300-millimetre wafer costing $15,000 to $20,000 at the leading edge, that yield gap is nearly a 2:1 effective cost per good die, and the gap has widened rather than narrowed across successive nodes. China’s two-decade, $150 billion semiconductor subsidy programme has left SMIC approximately two generations behind, with gross margins of 19% against TSMC’s 60%. Capital does not buy this. Morris Chang’s characterisation of TSMC Arizona as a “very expensive exercise in futility” was a statement about what operational capability requires, namely sustained co-presence and accumulated practice, neither of which capital can compress. The AI cycle is stressing TSMC’s advantage now; the advantage will persist after the cycle moves on, and TSMC will be making substantially more leading-edge logic at higher margins than it was pre-cycle, because leading-edge logic serves mobile, automotive, and industrial markets whose demand will have stepped up in the meantime.
ASML sits in the same category through a different mechanism: EUV systems depend on Zeiss optics produced under a craft tradition running back to 1846, and every leading-edge fab in the world depends on that single supply chain. The Western gas turbine majors, GE Vernova, Siemens Energy, and Mitsubishi Heavy Industries, are another instance. Their current backlog through 2028 is rent. But a heavy-duty gas turbine requires 50 years of metallurgical and combustion engineering to build reliably at scale, and that knowledge base does not transfer to a new entrant on any timescale capital cares about. Chinese competitors have been making serious turbines for two decades and still cannot compete at the heavy-duty frontier. When the AI-driven power cycle ends, the Western three will still be producing substantially more turbines than they did pre-cycle, because electrification of heating and transport, reshoring, and coal retirement will have become live demand drivers, and the market will still be paying these firms for the output.
NVIDIA looks like a classic Schumpeterian play, but the sheer complexity of what they ship (silicon, NVLink, rack-level thermal and power design, the CUDA-X library stack, co-design with hyperscaler customers) compounds into something closer to operational capability than to a technology lead. Trainium and TPUs have not materially bitten into NVIDIA’s margins despite years of hyperscaler investment, which is evidence for this read. They are more brittle than TSMC or ASML, because the paradigm they serve is younger and could shift, but they are not to be dismissed as a cyclical Schumpeterian position either.

4. What would change the view
Three categories of risk are worth naming. None delivers the commodity-style clearing event the glut thesis requires, but each changes parts of the allocation map in specific ways.
Technical change sits on two margins. The familiar one is a further architectural breakthrough in model efficiency, with DeepSeek V3’s $5.6 million pre-training run (the reported GPU rental cost, not the all-in research and capital figure) as the existence proof, which on a Jevons reading accelerates the thesis rather than breaks it, by activating use cases the current cost structure cannot support. Every prior compute-era efficiency jump has produced an order-of-magnitude expansion in total compute demand rather than a contraction. The less familiar risk is a substrate shift that resets operational-capability advantages specifically: neuromorphic, optical compute at scale, or a model architecture that makes current kernel libraries obsolete. This is the paradigm risk for the NVIDIA call, and to a lesser extent for the advanced-packaging layer. TSMC, ASML, and the turbine majors are less exposed because their capability base transfers across substrate generations. If an investor wants to hedge the NVIDIA call without stepping away from the broader thesis, the hedge is an overweight in the positions that survive the paradigm shift.
Geopolitics operates differently than it appears. The first-order effect, supply chain fragmentation, export controls on Chinese advanced computing, and tariffs on specialty materials, typically entrenches the operational-capability positions rather than eroding them, because substitution attempts fail on exactly the tacit-knowledge dimensions the taxonomy identifies. TSMC’s position has strengthened through the export control regime, not weakened. The Western gas turbine majors have benefited from restrictions on Chinese competitors’ access to Western markets. The second-order effect, a durable Taiwan contingency or a rupture in the Netherlands-Taiwan-US litho axis, is a genuine tail risk that would reset the taxonomy at the leading edge. This is a supply collapse risk, a different shape of loss from a glut, and one an allocator should hedge through geographic diversification within the operational-capability layer rather than by under-weighting the layer itself.
Macro compresses timing rather than changing structure. A recession delays the demand curve without bending it; the AI capex cycle is currently funded largely out of hyperscaler free cash flow, which is itself durable. The relay race runs slower in a downturn. The positions identified still pay, and the operational-capability compounders in particular tend to use downturns to widen their competitive position while capital-constrained competitors fall behind. Macro is a timing risk, not a thesis risk.
The scenario worth ending on, because it is the most plausible one that genuinely changes the analysis and the one that intensifies rather than weakens the thesis, is a robotics breakthrough. The current application of AI is, by historical GPT standards, narrow, and largely confined to productivity software. Embodied AI at commercial scale, general-purpose robotic labour, autonomous industrial systems at volume would extend the demand vector into a second physical stack that the software-era system does not use: battery cells, rare earth magnets, precision actuators, sensors, industrial metals, high-volume precision manufacturing capacity. Those inputs sit on a different supply geography (the lithium triangle, Chinese rare earth processing, Korean and Japanese battery chemistry, German and Japanese and Chinese precision manufacturing) with different constraint types and different geopolitical overlays. The software-era bottlenecks persist and a second set opens alongside them. The taxonomy does not break. It extends. Ricardian advantages emerge in new materials geographies. Schumpeterian advantages emerge at the battery, actuator, and sensor frontiers. Operational-capability advantages emerge in high-volume precision manufacturing, the kind Denso, Bosch, and the tier-one Chinese industrial integrators have spent decades accumulating. The stress test for this piece is a demand expansion into categories the current stack is not built for.
Demand responds at software speed; supply responds at physical speed; the gap between those response times is where institutional capital should sit. The layers where capital can respond freely are the glut layers, and the bottleneck-thinker’s most exposed trade. The layers where it cannot are the layers where durable returns accrue. The task is to be positioned at the second.